В этой статье я расскажу об одной необычной проблеме, с которой мне однажды пришлось столкнуться в процессе написания бота для одного сайта с авторизацией. Внимание: эта статья не для начинающих. Предполагается, что читатель уже имеет опыт веб-программирования и знаком с PHP, библиотекой CURL и основами HTTP.
Перейдем к описанию проблемы.
Как я уже упомянул, мне нужно было написать скрипт бота для одного сайта с целью автоматизации некоторого процесса из нескольких шагов, не считая авторизации. На первый взгляд, типичная задача. Впрочем, поначалу так оно и было. Т.к. на сайте применялась авторизация и активно использовались cookies, было решено использовать CURL. Я понемногу сниффил HTTP-запросы к серверу сайта и воспроизводил их у себя в скрипте. Процесс, как говорится, шел….
Неприятности начались на предпоследнем шаге, когда сервер совершенно неожиданно для меня отказался выдавать желаемый результат. Я довольно долго пребывал в состоянии ступора, продолжая снова и снова сравнивать логи «искусственных» и «естественных» (браузерных) запросов, в надежде найти хоть какое-то несовпадение. Прошло несколько часов, прежде чем я понял, что впустую трачу время.
И тогда я обратил свое внимание на JavaScript cookies, т.е. cookies, создаваемые кодом JavaScript. Разумеется, CURL не мог отследить их появление и соответственно не мог добавить их в свои запросы. Но зачем серверу проверять JavaScript cookies? Хороший вопрос.
Кстати, забегая вперед, скажу, что моя догадка оказалась верной. Сервер и в самом деле проверял JS куки, причем, только на том злополучном предпоследнем шаге. Что особенно странно, эти куки не были фиктивными: они использовались в коде на стороне клиента, но по какой-то причине находили также применение и на сервере.
Итак, мне предстояло решить следующие две задачи:
- найти «значимые» JavaScript cookies, которые влияют на ответ сервера;
- найти способ вставить эти куки в запросы CURL.
Насчет первой задачи мне, в принципе, было все ясно, во всяком случае, я уже представлял себе примерный план действий. Так что я решил сразу начать со второй: найти средство для добавления «своих» куков в CURL-запрос, дополнительно к тем, что появляются там автоматически, из файла, указанного опцией CURLOPT_COOKIEFILE.
Первым, что пришло мне в голову, была мысль: включить опцию CURLOPT_COOKIE со строкой, составленной из параметров куков. Примерно так:
curl_setopt($hc, CURLOPT_COOKIE, "name1=value1; name2=value2; ...");
Так я и сделал: добавил эту строку в код… и очень скоро убедился, что это не работает. Вернее работает, но совсем не так как мне хотелось. В отправленном HTTP-заголовке были только куки, добавленные этой опцией, а вот куки из файла CURLOPT_COOKIEFILE при этом исчезли (исчезли из заголовка, а не из файла). Т.е. содержимое файла-хранилища куков игнорировалось. Из этого следует простой и бесполезный вывод: опции CURLOPT_COOKIE и CURLOPT_COOKIEFILE/CURLOPT_COOKIEJAR нельзя использовать вместе.
К тому времени я уже видел два пути решения:
- отказаться от услуг CURL’а в плане автоматической обработки cookies и взять эту «черную» работу себе, т.е. самому парсить куки из заголовков ответа, сохранять их, и передавать вместе с запросами. Звучит немного пугающе, но зато это дает полный контроль над куками.
- оставить авто обработку cookies, но добавить возможность вставки в файл куков «своих» (кастомных) параметров. Тоже перспектива не из приятных, поскольку это предполагает ручную правку файла куков.
После недолгих колебаний был выбран второй вариант, т.к. он показался мне более легким в реализации. К тому же меня давно уже интересовал формат Netscape Cookie File, но не было повода познакомиться с ним поближе. И вот этот повод появился.
Искать информацию по этому формату долго не пришлось. С первой же страницы выдачи гугла я попал на оф. сайт CURL’а, в архив переписки пользователей с создателем этой библиотеки, где и нашел то что искал.
Формат файла оказался довольно простым – 7 полей (атрибутов) в каждой строке, разделенных tab’ами и идущих в таком порядке:
- domain
- tailmatch
- path
- secure
- expires
- name
- value
Смысл этих полей по-моему вполне очевиден. Отмечу только, что tailmatch – это флаг точного совпадения доменного имени сайта.
Теперь, когда формат файла был известен, остальное было уже делом техники.
В итоге мной был написан небольшой класс CookieJarWriter. Вот его код:
class CookieJarWriter
{
/**
* имя (путь) файла cookie
*/
protected $sFile = false;
/**
* массив значений общих полей записей в файле cookie
*/
protected $aPrefix = array(
'', // domain
'FALSE', // tailmatch
'/', // path
'FALSE', // secure
);
/**
* строка значений общих полей записей в файле cookie
*/
protected $sPrefix = '';
/**
* @param array $file -
* @param string $domain -
*/
function __construct($file, $domain = '') {
if (!$file)
return;
$this->sFile = $file;
$this->setPrefix($domain);
}
/**
* Инциализация/изменение общих полей записей в файле cookie
* @param string $domain - значение поля "domain"
* @param bool $bTail - значение общего поля "tailmatch"
* @param string $path - значение общего поля "path"
* @param bool $bSecure - значение общего поля "secure"
*/
function setPrefix($domain = null, $bTail = null, $path = null, $bSecure = null) {
if (!is_null($domain))
$this->aPrefix[0] = $domain;
if (!is_null($bTail))
$this->aPrefix[1] = $bTail ? 'TRUE' : 'FALSE';
if (!is_null($path))
$this->aPrefix[2] = $path;
if (!is_null($bSecure))
$this->aPrefix[3] = $bSecure ? 'TRUE' : 'FALSE';
if ($this->aPrefix[0])
$this->sPrefix = implode("\t", $this->aPrefix) . "\t";
}
/**
* Добавление/изменение/удаление записи в файл cookie
* @param string $name - имя параметра cookie (индивид-ое поле "name")
* @param string $value - значение параметра cookie (индивид-ое поле "value")
* @param int $life - срок хранения (в днях) записи cookie
* @return string|bool - содержимое записи либо результат удаления
*/
function setCookie($name, $value = null, $life = 1) {
if (!$this->sFile || !$this->sPrefix || !$name)
return false;
$cont = file_exists($this->sFile) ? file_get_contents($this->sFile) : '';
$cr = (strpos($cont, "\r\n") !== false) ? "\r\n" : "\n";
$a_rows = explode($cr, trim($cont, $cr));
$i_row = -1;
foreach ($a_rows as $i => $row) {
if (strpos($row, $this->sPrefix) === 0 &&
strpos($row, "\t" . $name . "\t") !== false) {
$i_row = $i;
break;
}
}
$ret = true;
if (!is_null($value)) {
// добавление/изменение:
$life = intval($life);
if ($i_row < 0)
$i_row = count($a_rows);
$n_exp = ($life > 0) ? (time() + $life * 24 * 60 * 60) : 0;
$a_rows[$i_row] = $ret =
$this->sPrefix . implode("\t", array($n_exp, $name, $value));
}
else if ($i_row >= 0) {
// удаление:
unset($a_rows[$i_row]);
}
file_put_contents($this->sFile, implode($cr, $a_rows) . $cr);
return $ret;
}
/**
* Добавление/изменение записи в файл cookie
* @param string $name
* @param string $value
* @param int $life
* @return string|bool
*/
function addCookie($name, $value, $life = 0) {
return $this->setCookie(array($name, $value, $life));
}
/**
* Удаление записи из файла cookie
* @param string $name
* @return bool
*/
function removeCookie($name) {
return $this->setCookie(array($name));
}
}
?>
Исходный код этого класса можно также найти на Гитхабе.
Итак, инструмент для «продвинутой» работы с куками был готов. Но на этом мои приключения не закончились. Предстояло еще отследить те самые «значимые» JS куки, понять какие значения им присваиваются и многое другое. По определенным причинам я не могу раскрыть здесь все подробности этого процесса, так же, как и назвать сайт, с которым работал. Вместе с тем, без практического примера использования рассмотренного инструмента данная статья выглядела бы незавершенной. Так что практическая часть здесь все-таки будет, но в упрощенной форме и на примере другого сайта, не требующего авторизации. Сайт этот — всем известный Яндекс-Каталог. Рассмотрим для примера категорию Фриланс.
Сначала эта страница выглядит так:
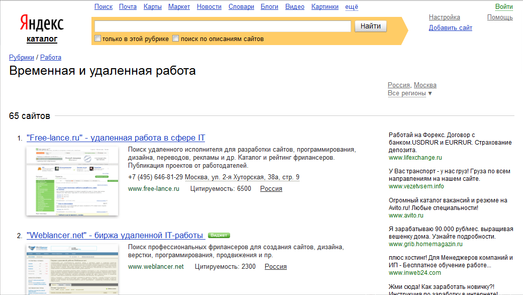
Но если перейти к настройкам, выбрать там пункт «стандартное с номерами» и вернуться на страницу каталога, то мы добъемся «чудесного» эффекта: превью со страницы исчезнут и останутся только «сухие» цифры и текст:
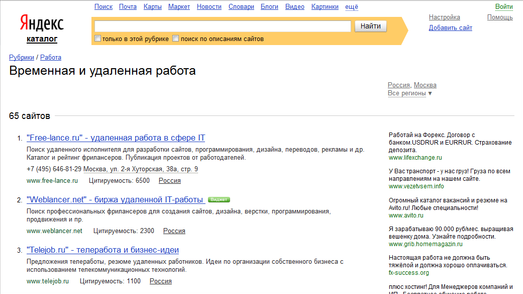
Давайте попробуем написать простейший бот для скачивания первой страницы этого каталога без превьюшек. Я понимаю, как глупо это выглядит со стороны: писать бот только для того чтобы изменить вид страницы. Но не забывайте, что это всего лишь пример. Давайте представим, что получение страницы без превьюшек – наше самое заветное желание).
Для начала проведем разведку. Обратим внимание на url страницы каталога после изменения настроек: он не изменился. Правда, к нему добавилась строка "?rnd=xxx", но это, по всей видимости, всего лишь указание браузеру не брать страницу из кэша. Отсюда можно сделать вывод, что настройки передаются и сохраняются, скорее всего, через куки.
Попробуем разобраться в том, как именно это происходит. В этом нам поможет такой полезный инструмент, как Live HTTP Headers. Это расширение Firefox’а позволяет отслеживать весь входящий и исходящий HTTP-траффик в браузере, в том числе и куки, посредством которых и осуществляется запоминание настроек в нашем примере. Происходит это, очевидно, после нажатия кнопки «Сохранить» и перехода к странице каталога.
Зайдем еще раз на страницу настроек, предварительно включив сниффер Live HTTP Headers. Выберем снова пункт «стандартное с номерами» и нажмем кнопку «Сохранить». А теперь посмотрим на наш улов в сниффере. Нас интересуют подробности запроса страницы каталога. У меня они имеют такой вид:
GET /yca/cat/Employment/Freelance/?rnd=191 HTTP/1.1 Host: yaca.yandex.ru User-Agent: ... Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: ru-ru,ru;q=0.8,en-us;q=0.5,en;q=0.3 Accept-Encoding: gzip,deflate Accept-Charset: windows-1251,utf-8;q=0.7,*;q=0.7 Keep-Alive: 115 Connection: keep-alive Referer: http://yaca.yandex.ru/setup.xml Cookie: yandexuid=796954901281541279; fuid01=4c62c49f04c00e82.pQ2hPKLWAnitiiTOBnW-nvOhiFssICTMfcKaMv0ZeTsFKaxVHOYxAPA2AGRsdF1qi3rm7fAKk77gJevuaNmhtnNUx_k0ykECc8bRJv3dUadZ_YDF1QLDZddTzYP_ZfOs; my=YwA=; L=eEAcXVFJR252Q0ADVkt9BW5wWmFyXXhXBkBYAwQaYmIRBgo6Ciw9ZggRFwUmNQwcOUs5LwQvVD42OjAPCmFfFQ==.1310050733.9042.213864.a4f928b9d113358bc254454a879f6c5c; yp=1636215158.sp.; yabs-frequency=/3/UOW2AQmAGyle0Ici2au0/; yaca_view=num
Здесь сразу бросается в глаза фрагмент "yaca_view=num". Скорее всего, это и есть наш искомый cookie-параметр. Но где он устанавливается? Во всяком случае не в заголовках ответа сервера, поскольку там этот параметр не встречается. Тогда логично предположить, что это JavaScript cookie и значит, его установка происходит где-то в джаваскриптах страницы настроек ("setup.xml"). Попробуем найти его в тексте этой страницы. Так и есть. Вот строка из файла "setup.xml":
$.cookie('yaca_view', $('input[name="yaca_view"]:checked' ).val());
По всей видимости здесь и происходит установка параметра "yaca_view" со значением, взятым из одноименного элемента формы (в нашем случае это значение ‘num’).
Итак, мы выяснили, что для того, чтобы увидеть страницу каталога без превьюшек, нужно передать серверу cookie-параметр с именем ‘yaca_view’ и значением ‘num’. Теперь, когда у нас уже есть средство для добавления cookies в CURL-запросы, можно без особого труда написать скрипт бота. Вот его код с небольшими комментариями:
require_once "CookieJarWriter.inc.php";
if (!function_exists('curl_setopt_array')) {
function curl_setopt_array(&$hc, $a_opts) {
foreach ($a_opts as $name => $val)
if (!curl_setopt($hc, $name, $val))
return false;
return true;
}
}
/**
* @param array $aOpts - массив значений опций CURL
* @param string $url - URL
* @param string $urlRef - URL реферера
* @return string|false
*/
function getByCurl($aOpts, $url, $urlRef = '') {
$hc = curl_init();
curl_setopt_array($hc, $aOpts);
curl_setopt($hc, CURLOPT_URL, $url);
curl_setopt($hc, CURLOPT_REFERER, $urlRef);
$cont = curl_exec($hc);
$b_ok = curl_errno($hc) == 0 && curl_getinfo($hc, CURLINFO_HTTP_CODE) == 200;
echo "\nSent HTTP Header:\n" . curl_getinfo($hc, CURLINFO_HEADER_OUT) .
"Content Length: " . strlen($cont) . "\n\n";
curl_close($hc);
return $b_ok ? $cont : false;
}
// Имя (путь) файла cookie:
$file_cook = dirname(__FILE__) . '/cookiejar.txt';
// Массив значений опций CURL:
$a_curl_opts = array(
CURLOPT_NOBODY => 0,
CURLOPT_RETURNTRANSFER => 1,
CURLOPT_CONNECTTIMEOUT => 10,
CURLOPT_TIMEOUT => 15,
CURLOPT_USERAGENT => 'Mozilla/5.0 Gecko/20110920 Firefox/3.6.23',
CURLINFO_HEADER_OUT => true,
CURLOPT_COOKIEFILE => $file_cook,
CURLOPT_COOKIEJAR => $file_cook,
);
define('URL1', 'http://yaca.yandex.ru/setup.xml');
define('URL2', 'http://yaca.yandex.ru/yca/cat/Employment/Freelance/?rnd=');
define('FILE_RESULT', 'result.htm');
echo '<h3>Trace Log:</h3><pre>';
$o_cw = new CookieJarWriter($file_cook, 'yaca.yandex.ru');
// Скачиваем страницу настроек:
getByCurl($a_curl_opts, URL1);
// Добавляем JS cookie-параметр:
$rec = $o_cw->addCookie('yaca_view', 'num');
echo "addCookie:\n" . ($rec ? "$rec\n" : "Fail\n");
// Скачиваем страницу каталога:
$cont = getByCurl($a_curl_opts, URL2 . rand(0, 999), URL1);
echo '</pre><br><hr><h3>Result: ';
if ($cont) {
file_put_contents(FILE_RESULT, $cont);
echo 'OK</h3><a href="' . FILE_RESULT . '" target="_blank">Result page</a>';
}
else
echo 'Fail</h3>';
На этом все. Спасибо за внимание.
P.S.: Эта статья в свое время была написана специально для Хабрахабра, где она и была впервые опубликована. Так же как и другие несколько статей, воспроизведенных в этом блоге.